 Population based reinforcement learning vs self-play
Population based reinforcement learning vs self-playAbstract
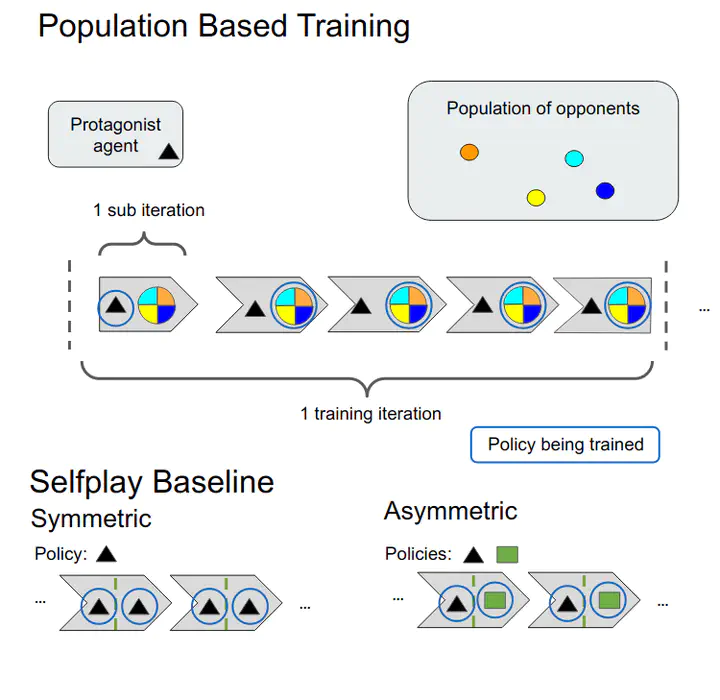
Self-play reinforcement learning has achieved state-of-the-art, and often superhuman, performance in a variety of zero-sum games. Yet prior work has found that policies that are highly capable against regular opponents can fail catastrophically against adversarial policies: an opponent trained explicitly against the victim. Prior defenses using adversarial training were able to make the victim robust to a specific adversary, but the victim remained vulnerable to new ones. We conjecture this limitation was due to insufficient diversity of adversaries seen during training. We propose a defense using population based training to pit the victim against a range of opponents. We evaluate this defense’s robustness against new adversaries in two low-dimensional environments. We find that our defense increases robustness against adversaries and show that robustness is correlated with the size of the opponent population.