Pavel Czempin
Pavel Czempin
Home
Publications
Light
Dark
Automatic
3
Improving Reward Learning by Estimating Annotator Expertise
Reinforcement learning from human feedback (RLHF) has been used successfully to teach robots tasks that are difficult to specify …
Pavel Czempin
,
Rachel Freedman
,
Ellen Novoseller
,
Vernon Lawhern
,
Cameron Allen
,
Erdem Bıyık
PDF
Cite
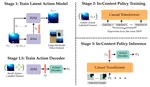
Clam: Continuous latent action models for robot learning from unlabeled demonstrations
Learning robot policies using imitation learning requires collecting large amounts of costly action-labeled expert demonstrations, …
Anothy Liang
,
Pavel Czempin
,
Matthew Hong
,
Yutai Zhou
,
Erdem Bıyık
,
Stephen Tu
PDF
Cite
DOI
In-Context Generalization to New Tasks From Unlabeled Observation Data
Large pretrained models in natural language processing and computer vision have achieved impressive capabilities by training on vast …
Anthony Liang
,
Pavel Czempin
,
Yutai Zhou
,
Stephen Tu
,
Erdem Bıyık
PDF
Cite
×